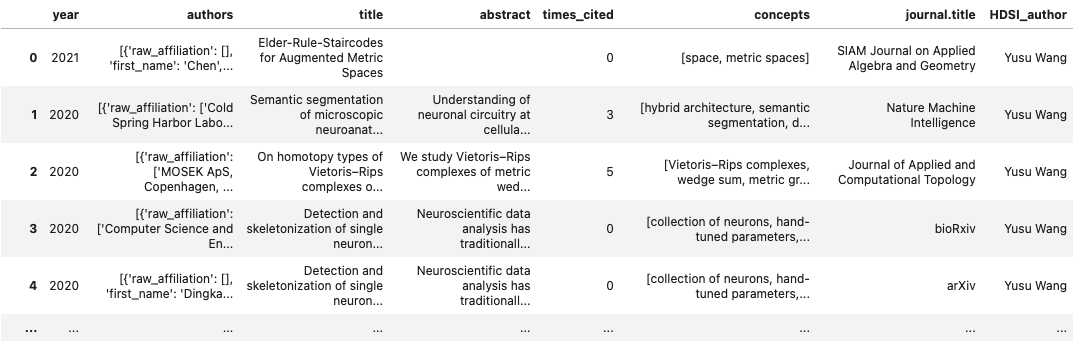
Methodology
In order to develop the domain speciality of each faculty member, we decided to perform NLP in the form of topic modeling. Topic modeling provides methods for automatically organizing, understanding, searching, and summarizing large text corpora.
Latent Dirichlet Allocation (LDA)
The specific form of topic modeling that we used was Latent Dirichlet Allocation (LDA). An LDA model can be represented by a graphical probabilistic model with three levels as shown in the figure below. The inner level represents the word level where: w denotes a specific word in a particular document, while z denotes the specific topic sampled for that particular word. The middle level represents the document level where: Θ represents the topic distribution for a particular document. The outer level represents the corpus level where: α and β represents the document topic density and the word topic density, respectively. LDA uses a generative probabilistic approach to model each topic as a mixture of a set of words and each document as a mixture of a set of topics.
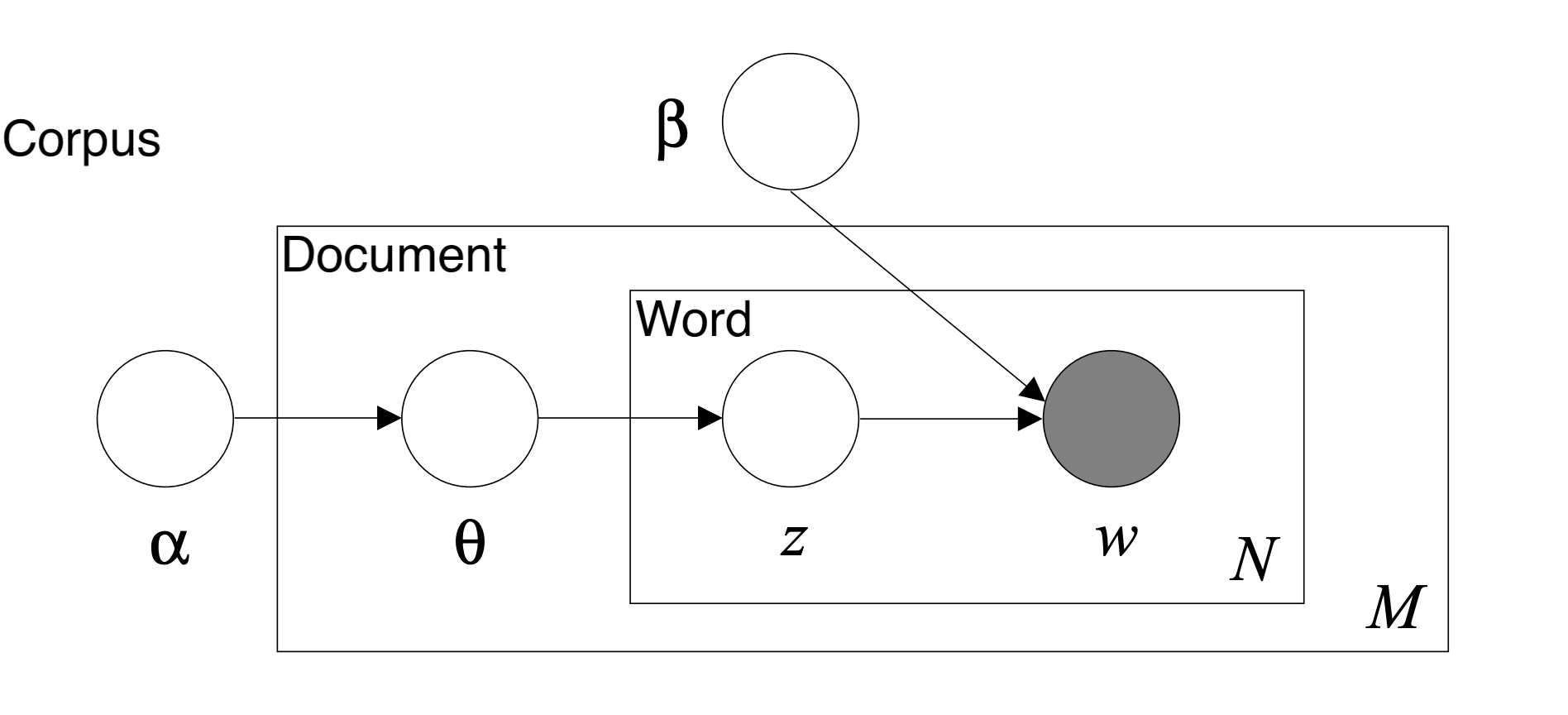
Behind the scenes, the LDA model takes the corpus of texts with the id2word indexes and transforms them into (1) a document topic density matrix and (2) a word topic density matrix by repetitive probabilistic sampling. The document topic density matrix contains the D number of documents as rows and K number of topics as columns. Each row represents the particular probability distribution over the generated topics for that particular document/article. The word topic density matrix contains V rows of unique words and K as the number of columns. Each row of this matrix represents a probability distribution of topics for a particular word. With the two matrices, we are able to generate a list of top terms for each topic ranked by the probability distribution. Additionally, we can extract the dominant topics for each terms by the measures in the document topic density matrix.
As a result, by running the LDA model, we will be able to obtain several matrices:
(1) word-topic matrix: represents each word with its associated topic distribution
(2) document-topic matrix:represents each document with its corresponding probability score
(3) author-topic matrix: aggregates from the document-topic matrices by the authors
(4) author-year-topic matrix: obtained by further aggregating the author-topic matrix by year
The difficulty lies in deciding the K variable, which in our case is the number of generated topics. Since this is a unsupervised machine learning method, human interpretation is required to account for the qualities of generated topics with different K's. This is why in our final dashboard we decided to include a toggle bar that accounts for different numbers of topics ranging from K = 5, 10, 15, 20, and 30. With this option, future users can interpret the results themselves based on how granular they want the topics to be.
Topic Labeling
Overall, we obtained labels from the LDA model, Dimensions, and Google Scholar to categorize articles and faculty. Below is a short explanation on how we gathered all the labels from these different areas.
LDA: we used the labels from our trained LDA model to represent our topics. By ranking each word by their topic probabilities, we can get each topic's top relevant words.
Dimensions API: we gathered labels from Dimensions API and combined them with the LDA labels to optimize our labels for topics. So each topic gets the most frequent topic labels aggregated on the topic level.
Google Scholar: we scraped the labels for each researcher from their Google Scholar pages.
Maintaining a Workflow
Since our tool aims to provide the information of faculty members at HDSI to industry partners, we want this tool to always stay updated and robust to changes. Therefore, we designed the following data pipeline that enables updates for our search tool:
- Data ETL: This part is done through an API call to the Dimensions database to extract the latest faculty publication data.
- Data Preprocess: This is the first part of the data pipeline which cleans up the retrieved datasets and preprocesses them for the later modeling use.
- LDA Modeling: The second part of the pipeline is dedicated to the modeling process. Here, developers can modify the configuration to adjust the topic models and explore the topic results.
- Prepare Dashboard: Based on the selected models, the pipeline will run the appropriate models and generate the necessary files for the use of dashboard.
- Launch Dashboard: Once all the data and files are ready, the dashboard is ready to be launched.
To look more closely at the data pipeline, please consult our project Github.